1. 분류 본능을 활용하라
테이블은 분류 대상을 갖고 있고, 인덱스는 분류 정보를 갖고 있고, 우리가 필요로 하는 분류 정보가 하나만 있어도 된다면 굳이 테이블과 인덱스를 분리돼 따로 존재할 필요가 없지만 다양한 분류 정보가 필요로 하기 때문에 대부분의 DB에서는 테이블과 인덱스는 분리돼 관리되고 있다.
1.1 인덱스 수는 적정해야 한다.
오라클에서 테이블은 분류 대상만을 가지게 됐고, 인덱스는 분류 정보만을 가지게 됐다. 테이블과 인덱스는 1:N 관계에 있으며 인덱스는 테이블에 종속적이다. 테이블이 삭제되면 인덱스는 자동으로 삭제된다. 그렇다면 하나의 테이블에 종속적인 인덱스의 개수가 많으면 많을수록 처리에서 많은 부하가 발생할 것이다. 대신 조회에서는 빠른 결과를 얻을 수 있다. 인덱스의 개수는 테이블의 성격에 따라서 접근하는 것이 좋다. 만약 테이블의 성격이 처리성 테이블이라면 가능한 적게 만들어야 할 것이며, 조회성 테이블이라면 많이 만들어도 부담이 없을 것이다.
테이블의 종류
코드성 테이블 : 필요한 만큼 인덱스 생성 가능
처리성 테이블 : 최소한으로 사용
집계성 테이블 : 필요한 만큼 적정하게 사용
로그성 테이블 : 필요없음
1번 코드성 테이블은 조회성 테이블로 생성 초반에 필요로 하는 데이터가 적재될 가능성이 많으며, 수시로 변화하거나 추가되는 일은 별로 없는 테이블이다. 따라서 처리에 대한 부담이 없으므로 필요한 만큼 만들어서 사용하면 된다. 단 비슷한 인덱스가 많이 생기면 인덱스 경합이 발생할 수 있으므로 그 부분만 주의하면 될 것이다.
2번 처리성 테이블은 인덱스가 많을수록 부하가 많이 발생할 것이다. 처리성 테이블의 성격은 동사적인 성격을 가지고 있는데, 예를들어 쇼핑몰에서 주문 테이블, 보험회사에서 계약 테이블 등으로 이런 동사적인 테이블은 조회(select)보다는 처리(insert, update, delete)에 더 많은 비중이 있는 테이블이므로 가능한 한 인덱스 개수를 최소화해야 한다.
3번 집계성 테이블은 대부분 데이터 적재가 야간 배치에서 발생하는 경우가 많다. 처리에 대한 부담보다는 조회에 비중이 있는 테이블이므로 인덱스가 많아도 무방하다.
4번 로그성 테이블은 조회의 비중이 거의 없는 테이블로, 인덱스가 없는 경우가 대부분이며 필요에 따라 PK 정도는 있을 수 있다. 그 PK도 데이터 추적에 용이한 시간의 정보를 갖고 있는 컬럼이면 충분할 것이다.
인덱스는 한번 만들면 삭제하기 어려우므로 만들기 전에 반드시 필요한 것인지 충분하게 고민해야 한다. 인덱스는 가능하면 적게 만들어서 사용할수록 DB 서버 부하가 낮다는 것은 자명하므로 인덱스가 너무 많다면 아래와 같은 내용도 인덱스 생성 여부를 결정하는 요소가 될 수 있다.
1. 쿼리 구동 시간이 낮인지 밤인지에 따라서 인덱스 생성 여부를 결정할 수 있다. (온라인, 배치)
2. 누가 사용하는지에 따라서 인덱스 생성 여부를 결정할 수 있다.(담당자, 관리자, 사장)
3. 얼마나 많이 구동되는지에 따라서 인덱스 생성 여부를 결정할 수 있다.
테이블의 크기가 수백 바이트 이내이거나 데이터 건수가 수백 건 이내인 소형 테이블일 때는 인덱스가 필요없다는 의견도 있는데, 그 정도 규모의 테이블이라면 대부분 코드성 테이블인 경우가 많다. 코드성 테이블에 있는 인덱스는 조건절에 사용되기보다는 조인절에 사용되는 경우가 더 빈번하므로 조인절에 사용하는 인덱스가 더 중요할 수도 있다.
1.2 인덱스는 위치정보와 순서정보로 구성된다.
인덱스는 기본적으로 위치 정보와 순서 정보의 특성을 동시에 갖고 있는 분류 정보이다. 예를들면 대형 할인매장에서 우유를 찾으려고 할 때, 일단 식품 코너는 찾을 것이며, 수많은 식품 코너에서 우유가 진열된 곳을 찾을 것이다. 또 본인이 좋아하는 특정 브랜드 우유를 찾을 것이며, 우리는 이미 알고 있는 위치정보로 여기까지 찾아왔다. 하지만 동일한 브랜드 우유라도 가장 신선한 우유를 원할 것이며, 식품 코너 분류 담당자가 제조일자(ASC)로 분류할지라도 여러분은 제조일자(DESC)로 찾을 것이다. 이렇듯 인덱스는 좀 더 광범위한 분류의 의미로 인식될 수 있다.
WHERE 구획 = '식품코너'
AND 제품 = '우유'
ORDER BY 제조일자 DESC위 쿼리에서 구획과 제품은 위치 정보를 가지고 있고, 제조일자 컬럼은 순서 정보를 갖고 있다. 우리는 다음 두 가지 경우의 인덱스를 고려할 수 있는데
1. 인덱스 1 = 구획 + 제품
2. 인덱스 2 = 구획 + 제품 + 제조일자(DESC)
두 가지 경우의 인덱스가 모두 가능하지만, 인덱스가 많을수록 DB에 부하가 올라가므로 동시에 만들면 안 된다는 사실을 알고 있다.
앞의 두 가지 인덱스에서 어떤 인덱스를 생성할 지 결정하는 기준은 일반적으로 CBO(Cost Based Optimizer)에서는 조건에 따른 Get Block 비용보다 소트 비용이 몇 배 더 높으므로 조건에 따른 데이터 결과 건수가 소트 비용을 감내 할 수 있다면 인덱스 1이 좋을 것이고, 감내할 수 없다면 인덱스 2가 좋을 것이다.
조건에 따른 데이터 결과 건수가 수백 건 단위라면 소트에 부담이 없다고 판단해 인덱스 1을 생성하고, 만약 수천 건 단위라면 인덱스 2를 생성한다. 물론 쿼리의 구동횟수에 따른 부하도 감안해 결정해야 한다.
WHERE 구획 = '식품코너'
AND 제품 = '우유'
AND 제조일자 BETWEEN '20140701' AND '20140707'
ORDER BY 제조일자 DESC, 제조번호 ASC앞 쿼리에서 구획, 제품, 제조일자, 제조번호 컬럼은 인덱스 후보컬럼이 될 수 있다. 만약 여러 개의 컬럼으로 인덱스를 생성하고자 한다면 고려해야 할 요소 중 하나가 바로 인덱스 컬럼의 순서이다. 다음의 규칙으로 인덱스 컬럼의 순서를 정하면 된다.
1. 위치정보 컬럼만으로 구성할 수 있다. 혹은 순서정보 컬럼만으로 구성할 수 있다.
2. 위치정보 컬럼과 순서정보 컬럼 순으로 구성할 수 있다.
3. 위치정보 컬럼과 순서정보 컬럼의 순서는 혼합되어서는 안 되며 뒤바뀌어서도 안된다.
구획 : 위치정보 컬럼 ('=' 조건)
제품 : 위치정보 컬럼 ('=' 조건)
제조일자 : 위치정보 + 순서정보 컬럼
제조번호 : 순서정보 컬럼
따라서 앞의 규칙을 적용하면 아래와 같은 인덱스를 구성할 수 있다.
인덱스 = 구획 + 제품 + 제조일자 + 제조번호
순서정보 컬럼은 반드시 위치정보 컬럼의 후행에 있다는 것을 명심하자.
1.3 조건절에 사용하는 인덱스와 조인절에 사용하는 인덱스
인덱스는 조건절에서 사용되기도 하고 조인절에서 사용되기도 한다. 조건절에서 사용하는 인덱스는 최초로 접근하는 테이블을 결정하는 중요한 인덱스이며, 데이터 접근 범위를 줄여주는 역할을 한다. 조인절에서 사용하는 인덱스는 테이블간의 관계를 맺는 인덱스로서, 항상 데이터 접근 범위를 줄여주는 것은 아니다. 1:N 관계의 테이블 조인에서는 오히려 접근 범위가 커지기도 한다. 오라클 쿼리에서 테이블간의 관계를 연결해주는 조인의 방법에는 Nested Loop Join, Sort Merge Join, Hash Join 세 가지가 있다. 온라인 쿼리에서 우리가 접하는 대부분의 조인 방법은 Nested Loop Join으로, Nested Loop Join만으로 구성된 쿼리에서는 오로지 하나의 조건절 인덱스와 조인절 인덱스로 구성된다. 따라서 우리가 접하는 대부분의 쿼리에서는 조건절 인덱스가 최초로 접근하는데 테이블을 결정한다고 해도 틀린 말은 아니다.
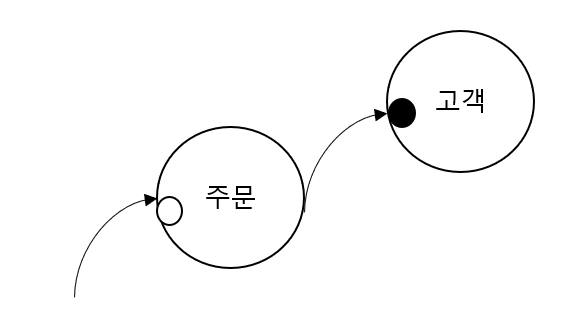
위와 같이 조건절에 인덱스가 없는 것보다 조인절에 인덱스가 없는 것이 성능 면에서 더 치명적일 수 있다. 조건절에 인덱스가 없다면 주문 테이블에서 풀스캔이 한 번 발생하며, 거기에서 얻어진 레코드 수만큼만 고객 테이블을 Index(Random Access)로 접근할 것이다. 만약 조인절에 인덱스가 없다면 테이블간 조인 방식에 따라서는 고객 테이블의 풀스캔이 한 번 혹은 그 이상 발생할 수도 있으니 조심해야 한다.
1.4 인덱스 생성/삭제 시 고려사항
인덱스는 만들었다고 모두 이용되는 것도, 사용하지 않는다고 바로 삭제 가능한 것도 아니다. 인덱스는 만들 때나 삭제할 때나 언제나 신중하게 접근해야 한다.
1. 신규 인덱스를 생성하기 전에 유사 인덱스가 존재하는지 확인
2. 신규 인덱스를 생성하기 전에 Index Split을 유발하지 않는지 확인
3. 신규 인덱스를 생성하기 전에 CBO 방식에서의 통계정보가 최신인지 확인
4. 기존 인덱스를 삭제하기 전에 사용하지않는 미사용 인덱스인지 반드시 확인
1번에 해당하는 경우를 간과한다면 인덱스끼리 경합이 발생할 수 있고, 기존 쿼리의 실행계획이 변동해 성능상 문제가 발생할 수 있다.
2번의 경우는 인덱스 분류 작업이 한 곳에 집중돼서, 동일한 Leaf block에 대해 과도한 Split이 발생한다면 성능상의 문제가 발생할 수도 있다.
3번의 경우는 인덱스를 생성할 테이블의 통계정보와 실제 정보간의 갭이 용인 가능한지 아닌지에 대한 문제이다. 급격하게 데이터가 증가하는 테이블에는 더욱 더 확인이 필요하다. 만약 통계 정보와 실제 정보가 현격하게 차이가 난다면, 인덱스가 생성되어도 이용되지 않을 가능성이 높다.
4번의 경우처럼 이미 만들어진 인덱스가 어떤 쿼리에서도 사용되지 않는 확신이 있어도 삭제하기가 쉽지 않으므로 조심해야 한다.
인덱스를 타지 않는 조건으로는 다음과 같다.
- 1.4.1 조건값이 컬럼 타입과 일치하지 않으면 인덱스를 타지 않는다.
- 1.4.2 조회 구간 범위가 크면 인덱스를 타지 않는다.
- 1.4.3 LIKE 문에서 값의 앞쪽에 %가 있으면 인덱스를 타지 않는다.
- 1.4.4 부정형 관련한 조건은 인덱스를 타지 않는다.
- 1.4.5 NULL 관련한 조건은 인덱스를 사용하지 않는다.
- 1.4.6 함수를 사용해 컬럼을 변형 시 인덱스를 타지 않는다.
1.5 결합인덱스의 컬럼 순서 결정방법
하나의 컬럼으로 만들어진 인덱스는 단일인덱스이고, 여러 컬럼으로 만들어진 인덱스는 결합인덱스라는 것을 알고 있다. 결합 인덱스에서는 컬럼들의 순서가 중요한 요소이다.
1. 공통적으로 사용하는 필수 조건절 컬럼을 우선
2. '=' 조건의 컬럼을 다른 연산자 컬럼보다 우선
3. 대분류 중분류 소분류 컬럼순으로 구성
4. 위치 정보 컬럼은 순서 정보 컬럼보다 우선
앞의 4가지 방법으로 결합 인덱스의 컬럼 순서를 결정할 수 있다. 각각의 방법간에는 우선 순위가 없으며 복합적으로 종합 판단해 결정해야 한다.
2. 오라클 인덱스 생성도의 비밀
2.1 오라클의 RBO 방식과 CBO 방식
RBO(Rule Based Optimizer)란 순위가 있는 규칙을 적용해 SQL에 대한 실행계획을 결정한다. 반면에 CBO(Cost Based Optimizer)는 SQL에 대한 최소한의 비용이 소요되는 실행계획(Plan)을 선택한다. 10g부터는 CBO만 지원하므로 CBO에 대해서만 알아보자.
CBO 방식은 주기적으로 통계정보를 갱신해 주어야 하는데, 통계정보를 근거로 해 여러 경우의 실행계획 중에서 가장 비용이 적게 드는 실행계획을 결정한다.
2.2 인덱스 생성도의 기본 규칙

첫째, 원은 테이블을 의미한다. (실선은 INNER JOIN 테이블, 점선은 OUTER JOIN 테이블)
둘째, 선은 조건절 혹은 조인절을 의미한다. (실선은 INNER JOIN, 점선은 OUTER JOIN)
셋째, 점은 인덱스를 의미한다. (채워진 점은 인덱스 있음을 의미, 빈 점은 인덱스 없음을 의미)
인덱스 생성도를 활용하면 복잡한 쿼리를 단순하게 보여줄 수 있고, 방향과 순서를 쉽게 알 수 있으며, 실행 계획을 이해할 수 있고 수립할 수도 있다. 또 생성해야 할 위치를 알 수 있으며 구성 컬럼을 알 수 있다.
2.3 인덱스 생성도에 대한 이해
CBO 방식에서 실행계획의 결정은 오라클이 주도적으로 하는 것처럼 보이지만, 실제로는 수동적인 역할만 수행한다. 현재 시점에 알고 있는 통계정보 범위 안에서 최소의 비용이 소요되는 실행계획을 보여주는 것뿐이다. 오라클은 인덱스가 없으면 풀스캔 실행계획을 보여줄 것이고, 잘못된 인덱스가 있다면 잘못된 실행계획을 보여주는 수동적인 역할만 한다.

위 생성도에서는 어떤 테이블에 먼저 접근할지 결정하는 것이 중요하다. 주문테이블을 먼저 접근하면 1번과 3번 컬럼에 인덱스를 생성해야 한다. 조인절에서 사용하고 있는 고객번호 컬럼은 분포도의 좋고 나쁨을 떠나서 무조건 표시해야 한다.주문일자 조건절을 통해 주문테이블을 먼저 접근하고, 이후 고객번호 조인절에 의해서 고객테이블을 접근함을 알 수 있다. 고객테이블의 고객명 컬럼은 인덱스가 없어서 컬럼값에 의한 필터만 발생한다.
만약 1, 2, 3, 4번 모두 인덱스가 존재한다면 양방향 접근이 가능하므로 오라클이 CBO 방식을 따른다면, 최소 비용이 소요되는 방향으로 결정할 것이다.(통계정보를 재생성, 힌트절을 통해 직접 방향을 결정할 수도 있음)
조인절에 인덱스가 없는 경우에는 양쪽 테이블에 각각 접근해 SORT MERGE 혹은 HASH JOIN으로 실행계획이 결정될 것이다. 만약 고객 테이블에서 주문 테이블로 접근 방향을 결정하고 싶다면, 2번 컬럼에 인덱스를 생성해야 한다.
3. SQL 작성의 규칙과 방법
3.1 공정쿼리
공정쿼리란 누구나 쉽게 쿼리를 작성하고 이해하는 것을 목표로 하는 것을 말한다. 개발자는 본인이 개발한 쿼리를 다른 개발자가 보기 쉽게 할 수 있도록 공정하게 쿼리를 작성해야 한다. 쿼리는 무엇을 조회할지에 대한 쿼리 결과도 중요하지만, 어떻게 조회할지에 대한 쿼리 과정도 중요하다. 공정쿼리로 작성한 쿼리에서는 쿼리의 결과뿐 아니라, 생성해야 할 인덱스 정보와 접근돼야 할 실행계획 정보까지 모두 알 수 있다.
3.2 공정쿼리 작성
SELECT *
FROM 고객, 주문, 부서
WHERE 고객.고객번호 = 주문.고객번호
AND 주문.부서번호 = 부서.부서번호(+)
AND 고객.고객명 LIKE ?
AND 고객.성별 = ?
AND 주문.상품코드 = ?
AND 주문.주문일자 = ?
AND 주문.배송여부 = ?
AND 부서.사용여부(+) = ?위 쿼리를 보면서 먼저 고객명 컬럼은 LIKE 이므로 인덱스 후보컬럼으로 곤란하다. 또 성별, 배송여부, 사용여부 컬럼은 분포도가 나빠서 인덱스 후보 컬럼으로 곤란하다.
최소비용 테이블 접근 순서는 다음과 같다. (주문 -> 고객 -> 부서) 부서는 OUTER JOIN이므로 마지막에 접근한다.
인덱스는 항상 목적지 컬럼에 생성한다.
참조
http://www.yes24.com/Product/Goods/61583758
개발자를 위한 인덱스 생성과 SQL 작성 노하우 - YES24
『개발자를 위한 인덱스 생성과 SQL 작성 노하우』개발 현장에서 바로 통하는 인덱스 생성 및 쿼리 작성 노하우 제시관리를 쉽게 하고 개발 생산성을 끌어올리는 쿼리 작성의 정석 ‘공정쿼리’
www.yes24.com
'DB' 카테고리의 다른 글
| 오라클의 조인 방식 (0) | 2022.08.01 |
|---|---|
| 공정쿼리 (0) | 2022.07.31 |
| 인덱스에 대한 오해와 진실 (0) | 2022.06.29 |
| 커넥션과 서버 프로세스의 생성 (0) | 2022.05.30 |
| 오라클 구조 (0) | 2022.05.01 |